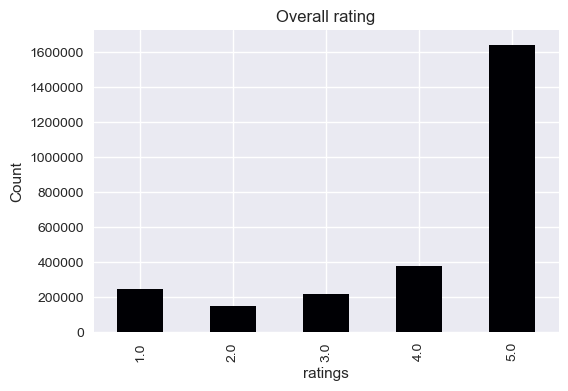
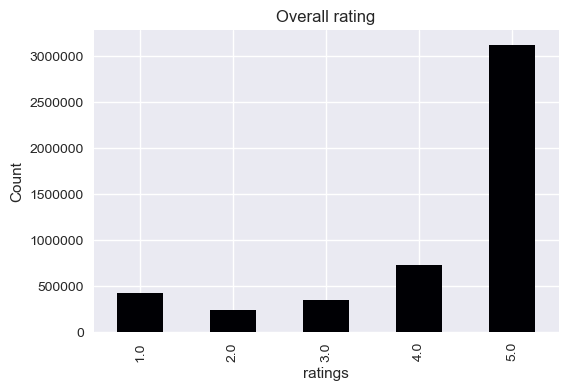
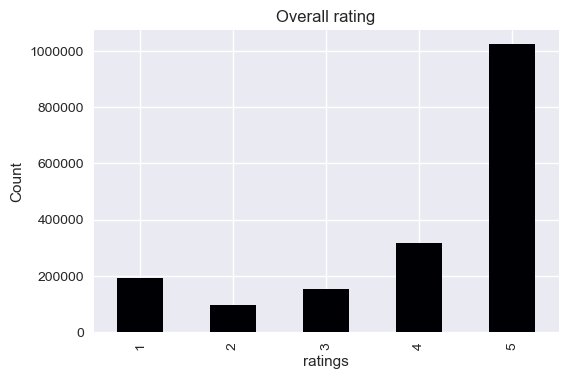
Most of the ratings are good (5’s and 4’s), which mean that customer’s should be pretty satisfied. We’re going to go and look closer the the textual reviews to see if they confirm this hypothesis (hopefully otherwise we’re quite in trouble)
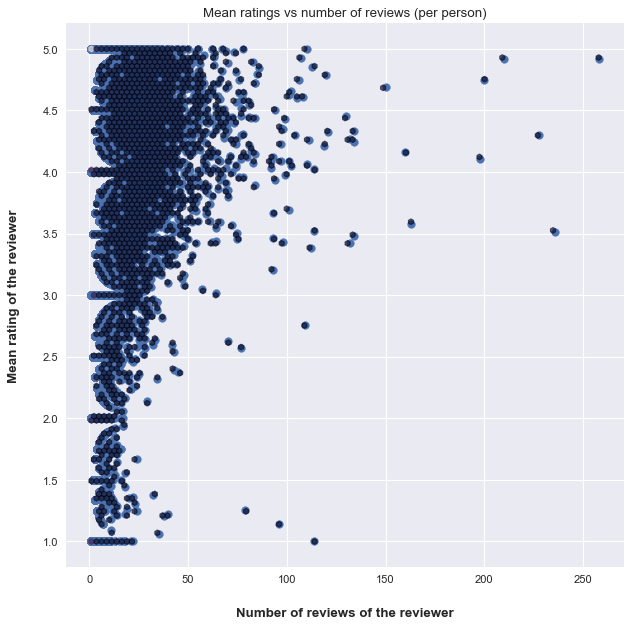
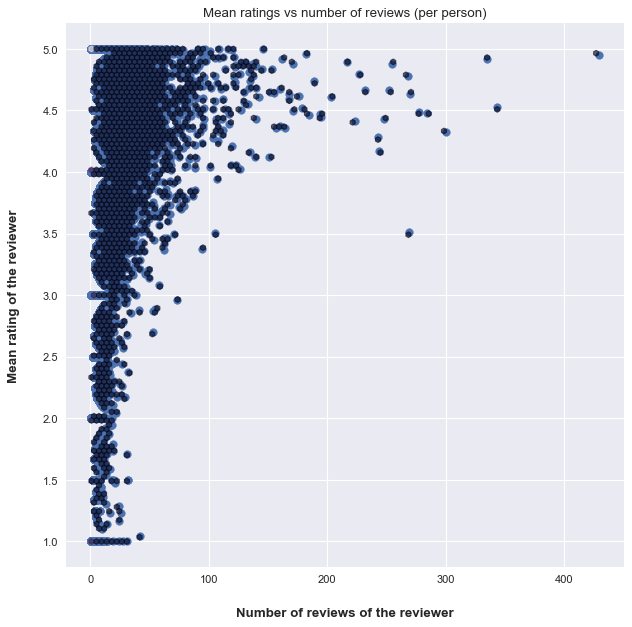
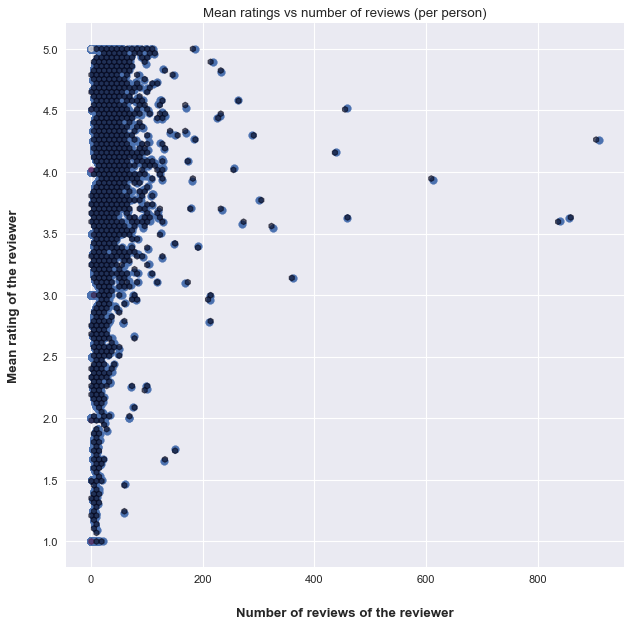
This plot is special, we can see that people who review a lot of products are not numerous, and then the majority of reviews are from peple who have less then 50 reviews. The shape is unique and we kan see that many people give the same ratings at each time ( not so likely that the mean is an integer), we can see that on horizontal lines of the (1,2,3,4 and 5 stars ratings).
We have used VaderSentiment analyser to get the sentiment classification based on the compound. Even if this analyser was trained on tweets, we assume in a first place that the content is going to be almost the same. BUT, we don’t only have textual reviews but also a summary of the reviews that should basically summarize the summary. Hence, the sentiment class should be the same as the main textual reviews, we’re going to apply the sentiment analyser on both features and see how does it stick to the numerical ratings.
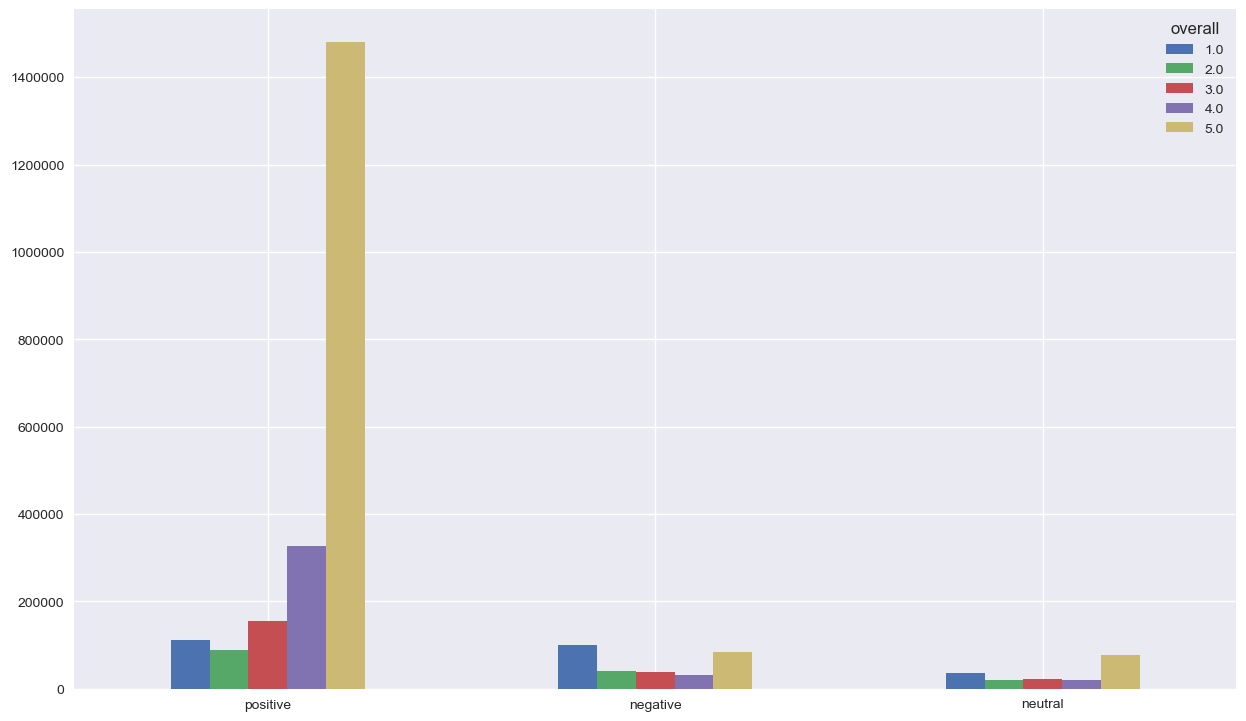
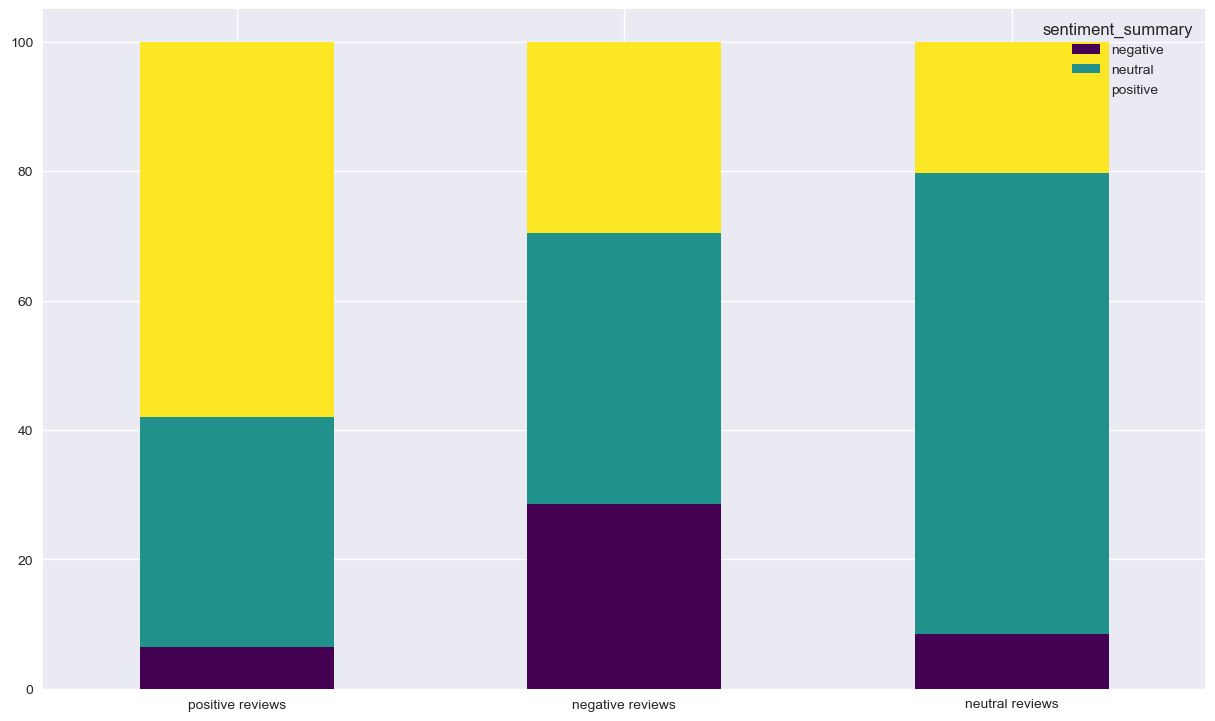
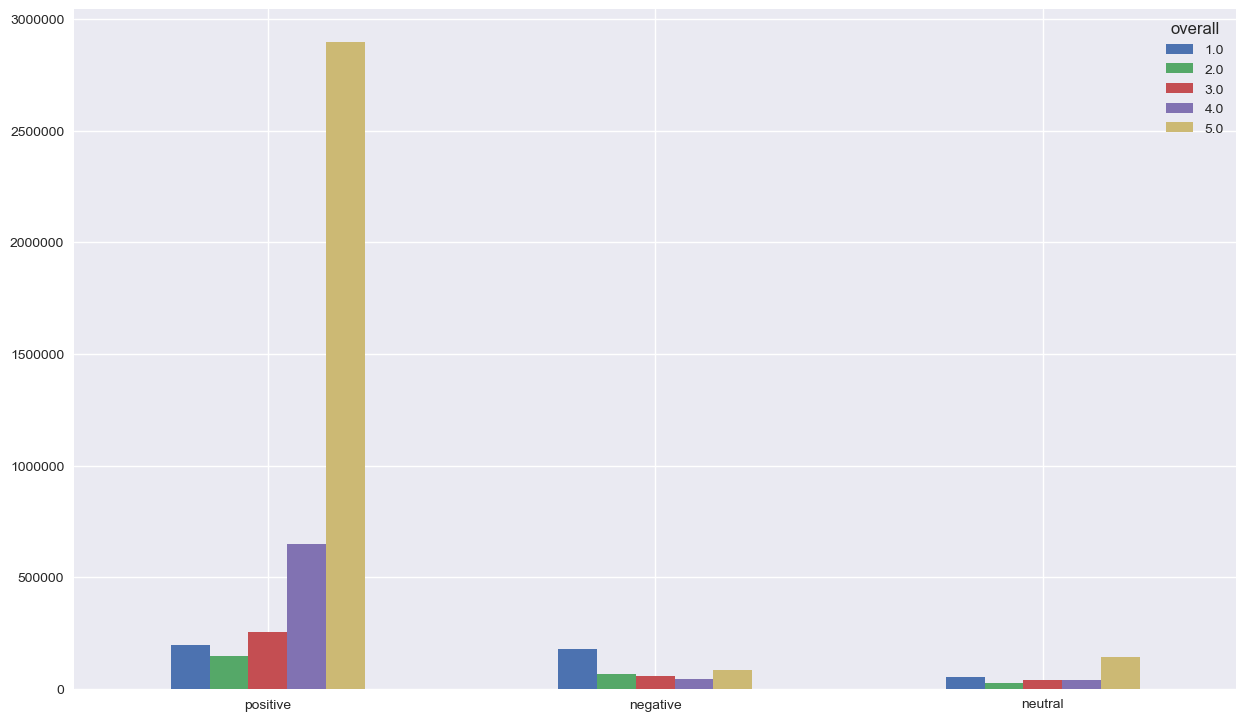
No problem seen with the classified positive reviews, since the majority of them have 5’s and 4’s reviews. We don’t need to dig deeper for the classified neutral reviews. However, it’s interesting to focus on the classified negative reviews since we have a lot of 5’s in there. Something strange is going on !! Let’s check the distribution of the reviews’s based on the summary classification of sentiment
We can observe the same thing for positive and neutral, but we have less 5’s for the classified negative reviews. The sentiment analysis was made by the same analyser, which confirm that there is a problem somewhere. We’re getting closer !
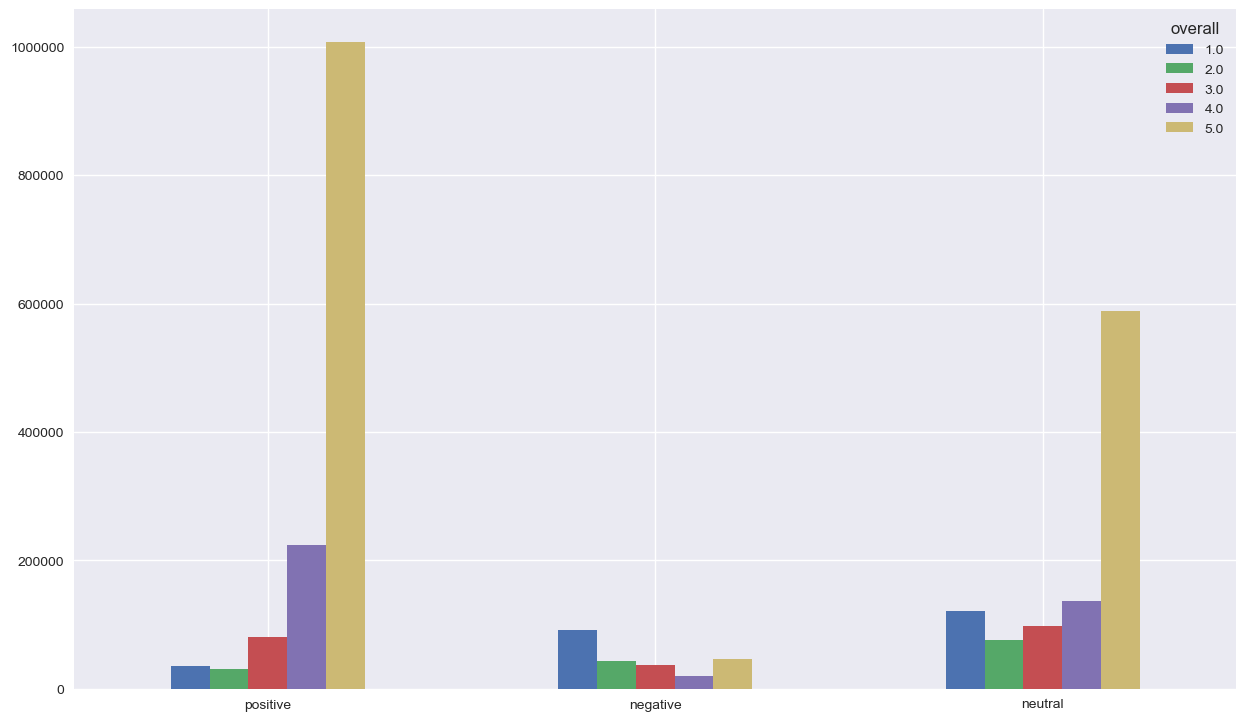
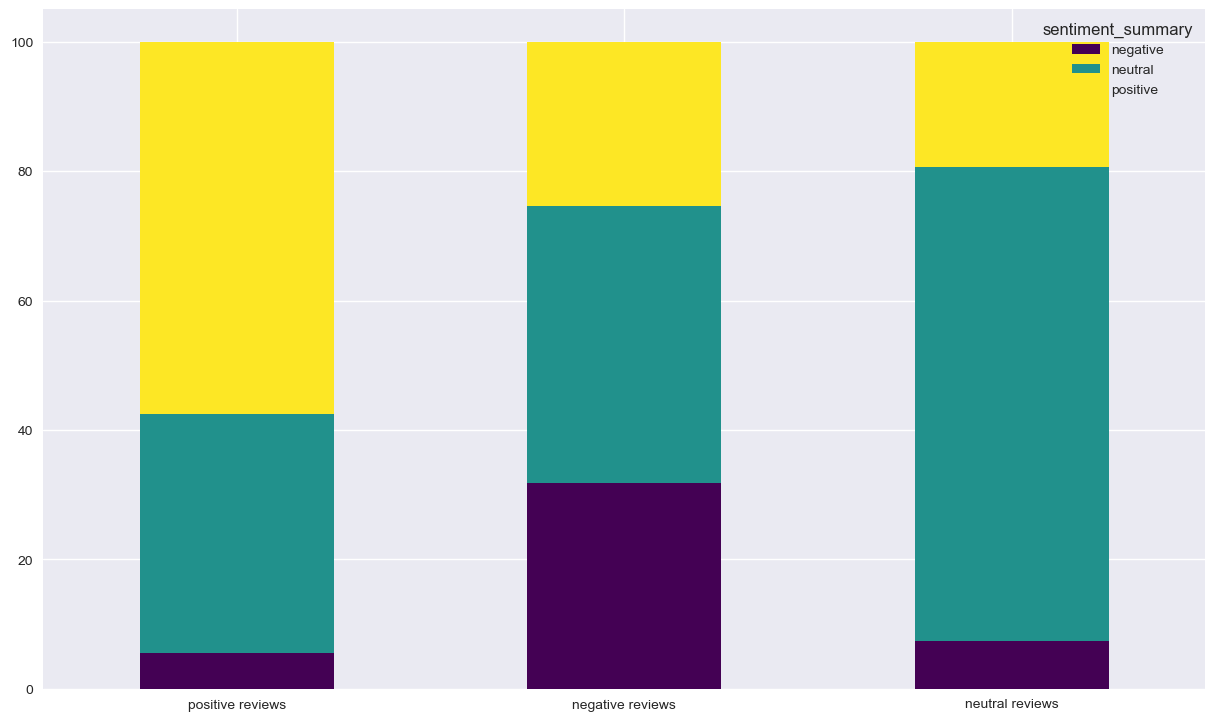
Now we’re going the show the proportions of summary classification on the 3 categories of classified reviews (positive, negative and neutral) We’re not going to handle neutral reviews because it’s always hard and try to look for insights in doubtful data (neutral can be anything that’s not extreme)
For positive reviews, we have a minority of negative summaries. It’s strange but not alarming. The alarming case is that reviews with negative sentiment on review and summary are less then 30 %, which somehow confirmes that we do have a real problem here !
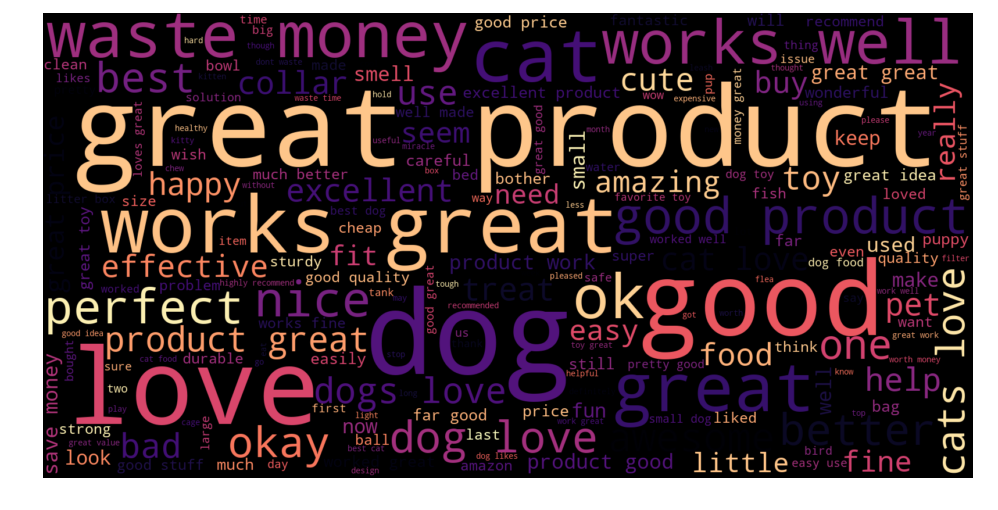
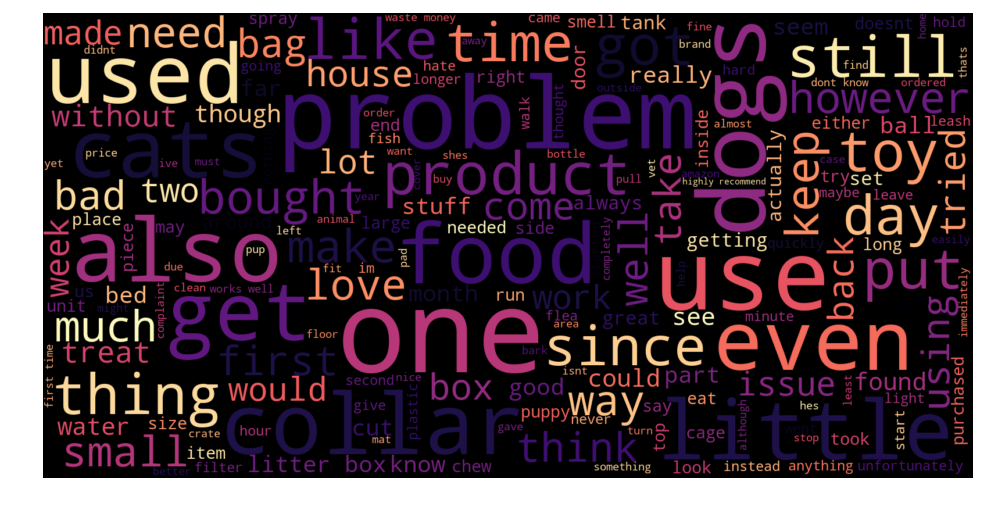
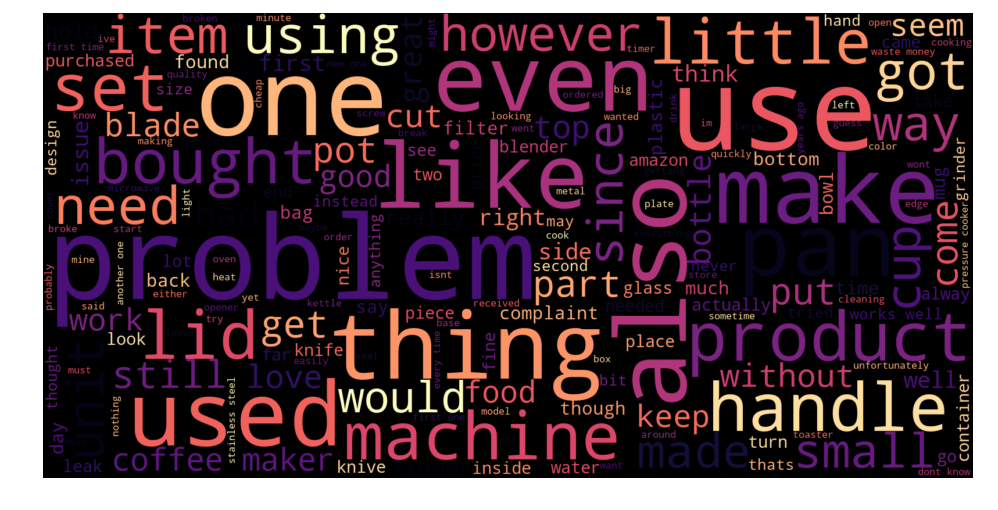
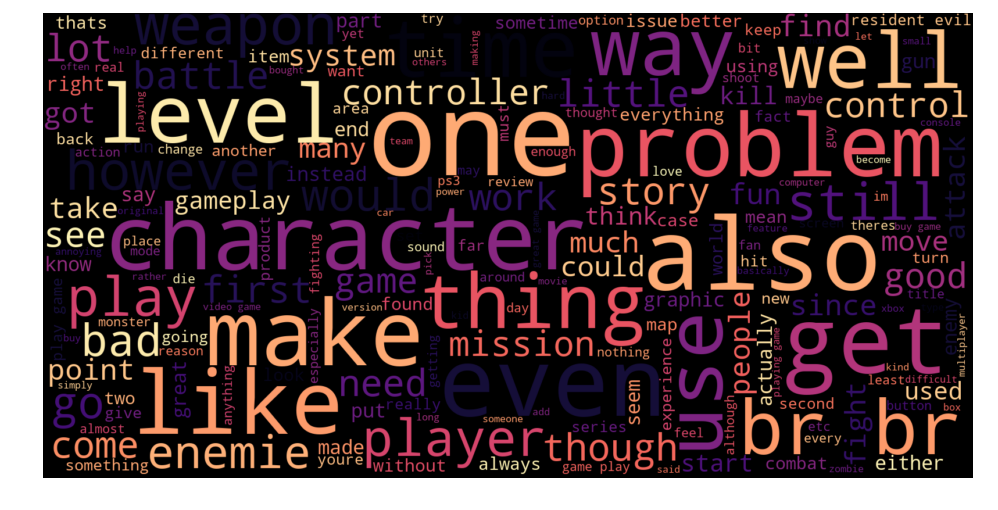
We chose to display the dominant words in both summaries (left) and reviews (right) separately, for the reviews who had positive summary and negative review content ! The size of each word depends on the number of occurrences.
The presence of words like : « Great, good, ok, fun, ,,, » in summaries of negative reviews is quite strange and incoherent. It’s normal to get a positive prediction. It’s also misleading because the classifier is much more likely to make mistakes on long texts then on a short summary.
We are going to build and train our own model in order to try and predict the sentiments from the text review.
To do that, we used a Long Short Term Memory network, which is a special kind of RNN, capable of learning long-term dependencies. They work tremendously well on a large variety of problems of natural language processing, and are now widely used. LSTMs are explicitly designed to avoid the long-term dependency problem. Remembering information for long periods of time is practically their default behavior, not something they struggle to learn! It is very practical in our case because it aims to detect tone's changement in a review to maximize the chances of a successful learning. We train this model with 70% of the reviews. To do so, we defined a threshold in numerical ratings (the threshold that gave us the best accuracy) which is to consider:
- 5's and 4's as positive
- 3's and 2's and ones as negative!
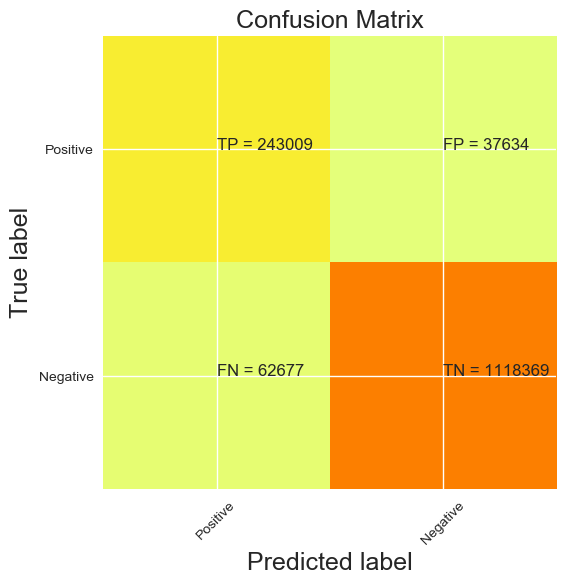
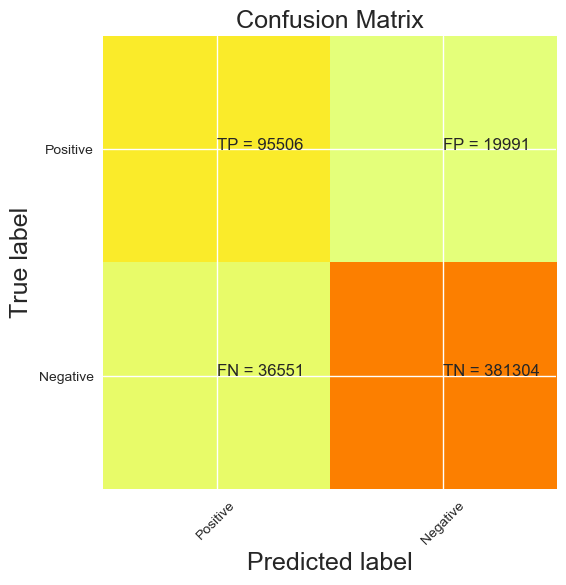
With this configuration, we have the following results presented in the confusion matrix
Accuracy :
91.8 %
P.S : the negative and positive are inverted
This analysis was quite long and tiring, with many moments of hesitation and ideas' dropping. But, we finally focused on deep textual analysis and differences between the summary and the main review. We know now for sure that the reviews (and every text written by customers on people on social media) is not 100% reliable. In fact, even if everything was fine and coherent, NLP is very subjective and everything depends on small details: (choice of words, text's lenght, capitalization..)
After training our own model, we achieved good predictions and overall scores, but it is always hard to deal with what people write. Sometimes they are happy with the products but still complain about a detail, or they use a neutral language which makes it even harder to detect the sentiment. Some customers are funny or sarcastic, which is sometimes difficult for humans to understand, let alone an algorithm! (the famous summary "TOO GOOD TO BE TRUE").
We worked on different categories to try and see different behavior, which is kind of true when we focus on the lexical background of users but the overall insights are present everywhere! Such datasets and very rich and can serve for many other topics, but it is also difficult to work with without making assumptions, or at least without checking the veracity of each claim we made.
Most of the ratings are good (5’s and 4’s), which mean that customer’s should be pretty satisfied. We’re going to go and look closer the the textual reviews to see if they confirm this hypothesis (hopefully otherwise we’re quite in trouble)
Same as "Pet supplies", a spcial distribution but in addition, we can see that customers with more than 100 reviews have a high mean rating ( > 3 ). It means that only customers satisfied with the products keep rating Amazon's items, the others either stop reviewing, or stop buying!
We have used VaderSentiment analyser to get the sentiment classification based on the compound. Even if this analyser was trained on tweets, we assume in a first place that the content is going to be almost the same. BUT, we don’t only have textual reviews but also a summary of the reviews that should basically summarize the summary. Hence, the sentiment class should be the same as the main textual reviews, we’re going to apply the sentiment analyser on both features and see how does it stick to the numerical ratings.
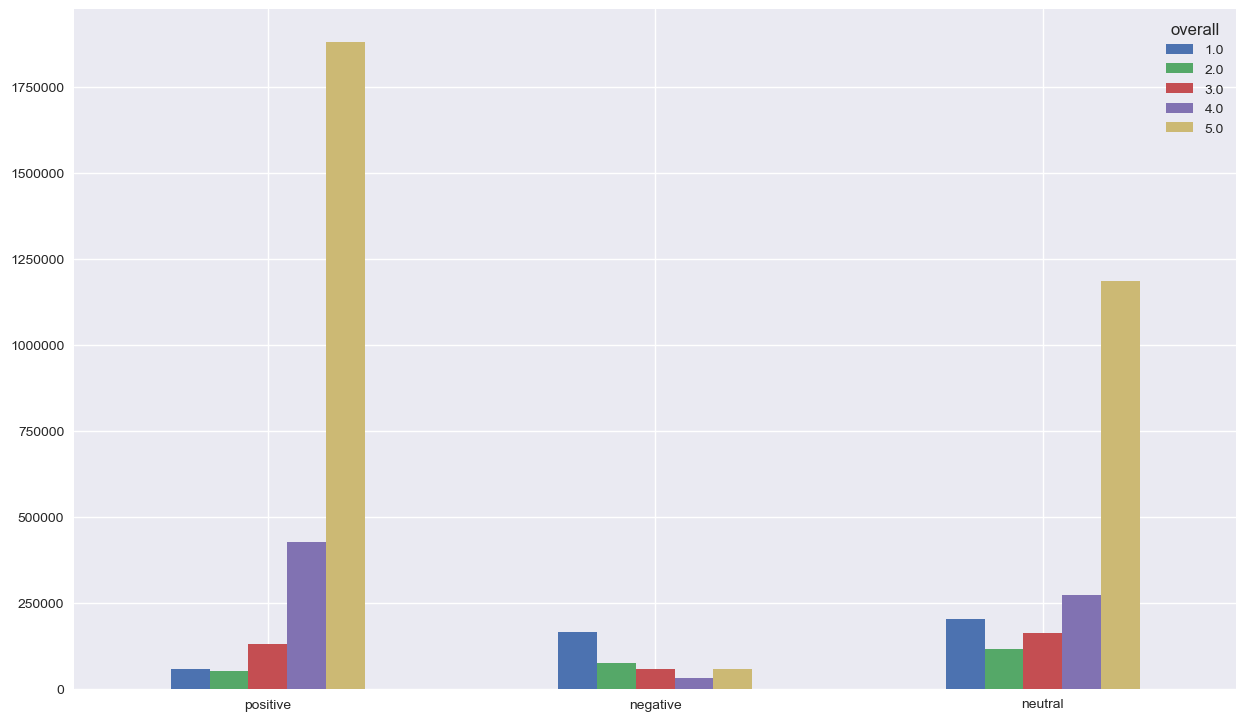
No problem seen with the classified positive reviews, since the majority of them have 5’s and 4’s reviews. We don’t need to dig deeper for the classified neutral reviews. However, it’s interesting to focus on the classified negative reviews since we have a lot of 5’s in there. Something strange is going on !! Let’s check the distribution of the reviews’s based on the summary classification of sentiment
We can observe the same thing for positive and neutral, but we have less 5’s for the classified negative reviews. The sentiment analysis was made by the same analyser, which confirm that there is a problem somewhere. We’re getting closer !
Now we’re going the show the proportions of summary classification on the 3 categories of classified reviews (positive, negative and neutral) We’re not going to handle neutral reviews because it’s always hard and try to look for insights in doubtful data (neutral can be anything that’s not extreme)
For positive reviews, we have a minority of negative summaries. It’s strange but not alarming. The alarming case is that reviews with negative sentiment on review and summary are less then 35 %, which somehow confirmes that we do have a real problem here !
We chose to display the dominant words in both summaries (left) and reviews (right) separately, for the reviews who had positive summary and negative review content ! The size of each word depends on the number of occurrences.
The presence of words like : « Nice, perfect, excellent, works, well, best loved, love, awesome ... » in summaries of negative reviews is quite strange and incoherent. It’s normal to get a positive prediction. It’s also misleading because the classifier is much more likely to make mistakes on long texts then on a short summary.
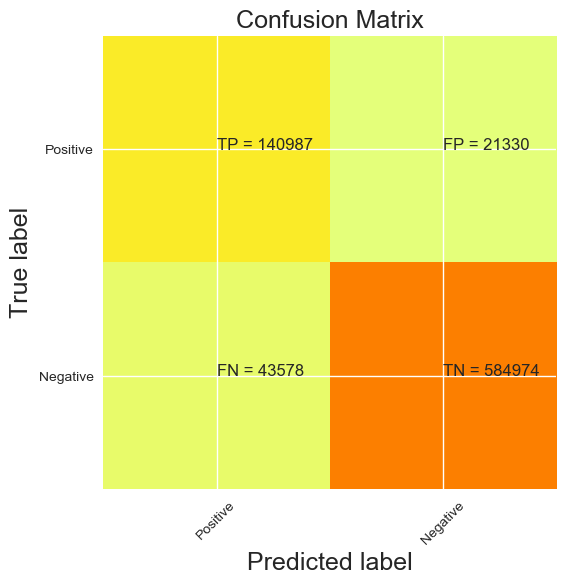
Same model, same threshold as for the pets supplies analysis
Accuracy : 91.26 %
P.S : the negative and positive are inverted
This analysis was quite long and tiring, with many moments of hesitation and ideas' dropping. But, we finally focused on deep textual analysis and differences between the summary and the main review. We know now for sure that the reviews (and every text written by customers on people on social media) is not 100% reliable. In fact, even if everything was fine and coherent, NLP is very subjective and everything depends on small details: (choice of words, text's lenght, capitalization..)
After training our own model, we achieved good predictions and overall scores, but it is always hard to deal with what people write. Sometimes they are happy with the products but still complain about a detail, or they use a neutral language which makes it even harder to detect the sentiment. Some customers are funny or sarcastic, which is sometimes difficult for humans to understand, let alone an algorithm! (the famous summary "TOO GOOD TO BE TRUE").
We worked on different categories to try and see different behavior, which is kind of true when we focus on the lexical background of users but the overall insights are present everywhere! Such datasets and very rich and can serve for many other topics, but it is also difficult to work with without making assumptions, or at least without checking the veracity of each claim we made.
Most of the ratings are good (5’s and 4’s), which mean that customer’s should be pretty satisfied. We’re going to go and look closer the the textual reviews to see if they confirm this hypothesis (hopefully otherwise we’re quite in trouble)
This plot is special, we can see that people who review a lot of products are not numerous, and then the majority of reviews are from peple who have less then 50 reviews. The shape is unique and we kan see that many people give the same ratings at each time ( not so likely that the mean is an integer), we can see that on horizontal lines of the (1,2,3,4 and 5 stars ratings).
We have used VaderSentiment analyser to get the sentiment classification based on the compound. Even if this analyser was trained on tweets, we assume in a first place that the content is going to be almost the same. BUT, we don’t only have textual reviews but also a summary of the reviews that should basically summarize the summary. Hence, the sentiment class should be the same as the main textual reviews, we’re going to apply the sentiment analyser on both features and see how does it stick to the numerical ratings.
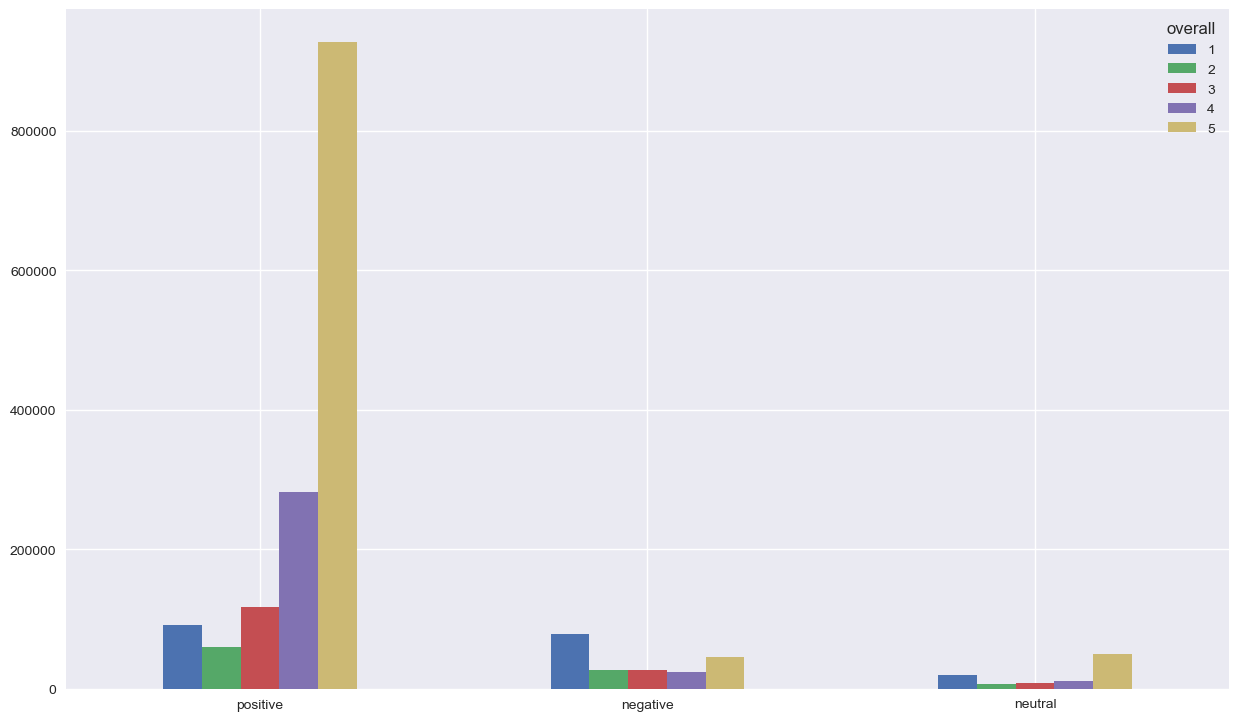
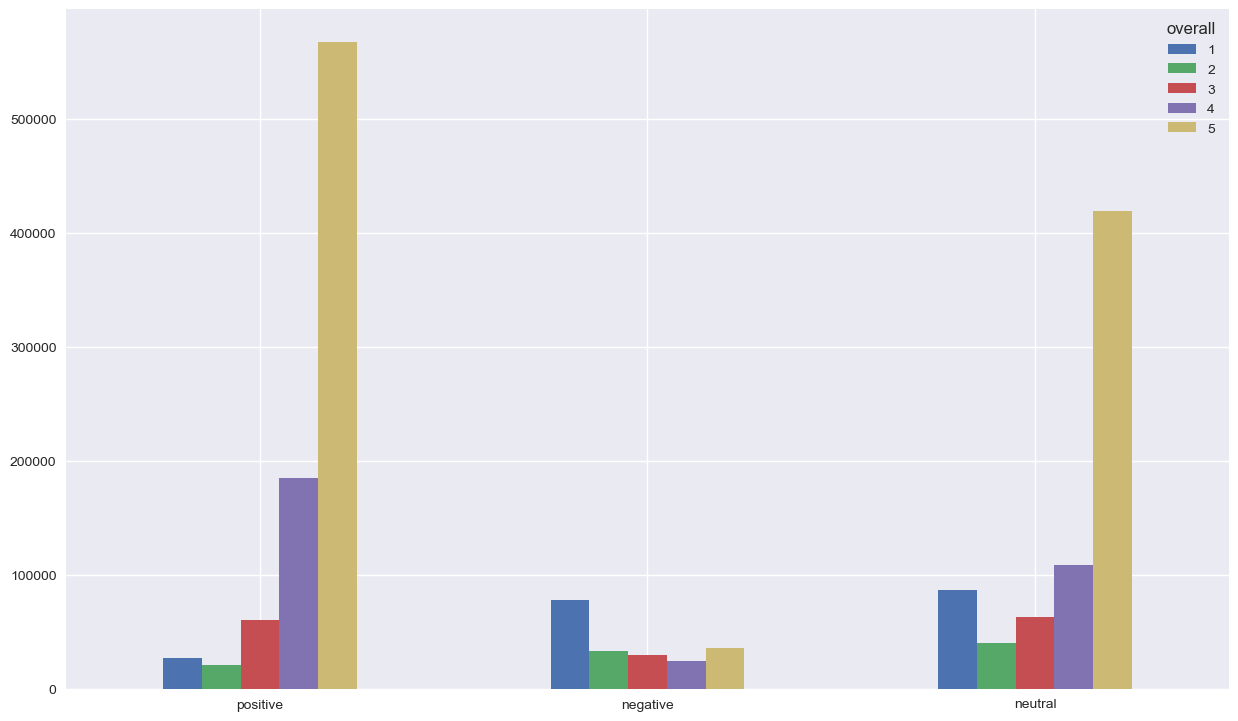
No problem seen with the classified positive reviews, since the majority of them have 5’s and 4’s reviews. We don’t need to dig deeper for the classified neutral reviews. However, it’s interesting to focus on the classified negative reviews since we have a lot of 5’s in there. Something strange is going on !! Let’s check the distribution of the reviews’s based on the summary classification of sentiment
We can observe the same thing for positive and neutral, but we have less 5’s for the classified negative reviews. The sentiment analysis was made by the same analyser, which confirm that there is a problem somewhere. We’re getting closer !
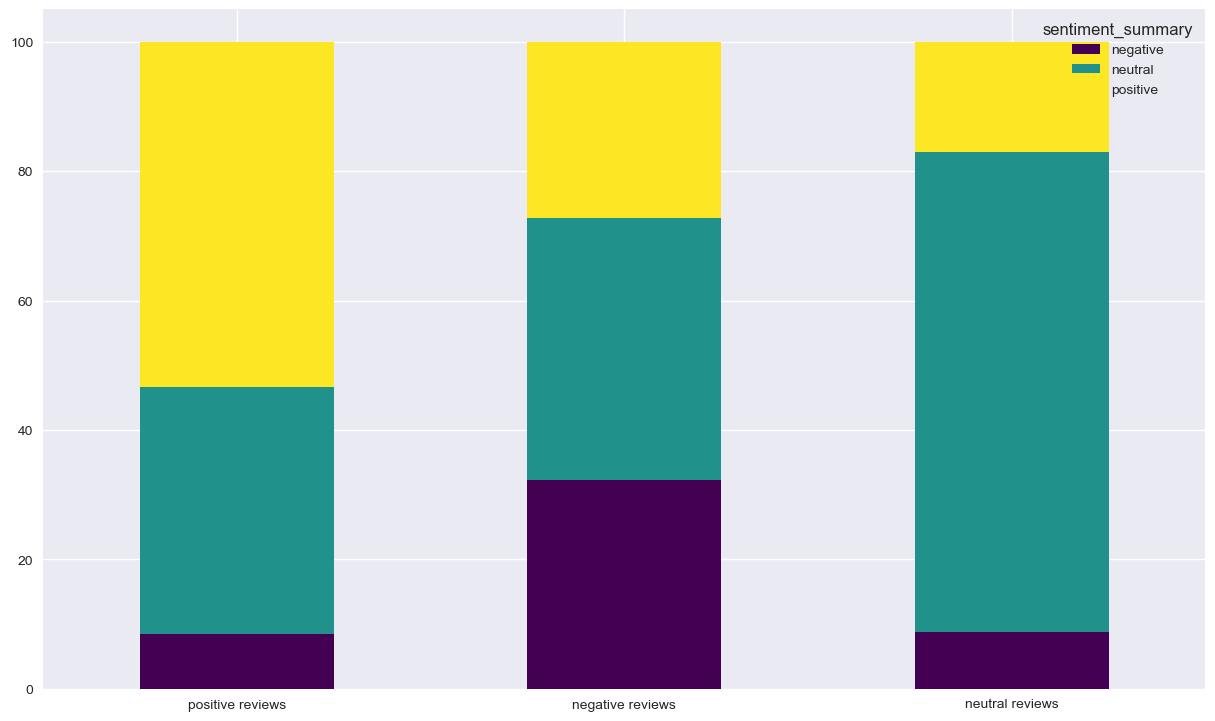
Now we’re going the show the proportions of summary classification on the 3 categories of classified reviews (positive, negative and neutral) We’re not going to handle neutral reviews because it’s always hard and try to look for insights in doubtful data (neutral can be anything that’s not extreme)
For positive reviews, we have a minority of negative summaries. It’s strange but not alarming. The alarming case is that reviews with negative sentiment on review and summary are less then 35 %, which somehow confirmes that we do have a real problem here !
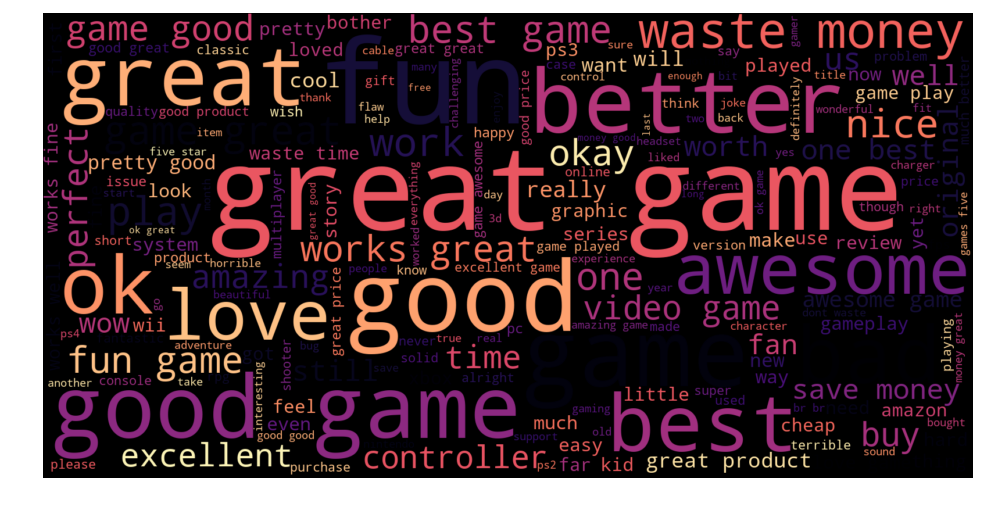
We chose to display the dominant words in both summaries (left) and reviews (right) separately, for the reviews who had positive summary and negative review content ! The size of each word depends on the number of occurrences.
The presence of words like : « Great, better, good, awesome, nice, ,,, » in summaries of negative reviews is quite strange and incoherent. It’s normal to get a positive prediction. It’s also misleading because the classifier is much more likely to make mistakes on long texts then on a short summary.
Same model, same threshold as for the pets supplies analysis
Accuracy : 95.94 % (best accuracy so far but we had less reviews than other categories)
P.S : the negative and positive are inverted
This analysis was quite long and tiring, with many moments of hesitation and ideas' dropping. But, we finally focused on deep textual analysis and differences between the summary and the main review. We know now for sure that the reviews (and every text written by customers on people on social media) is not 100% reliable. In fact, even if everything was fine and coherent, NLP is very subjective and everything depends on small details: (choice of words, text's lenght, capitalization..)
After training our own model, we achieved good predictions and overall scores, but it is always hard to deal with what people write. Sometimes they are happy with the products but still complain about a detail, or they use a neutral language which makes it even harder to detect the sentiment. Some customers are funny or sarcastic, which is sometimes difficult for humans to understand, let alone an algorithm! (the famous summary "TOO GOOD TO BE TRUE").
We worked on different categories to try and see different behavior, which is kind of true when we focus on the lexical background of users but the overall insights are present everywhere! Such datasets and very rich and can serve for many other topics, but it is also difficult to work with without making assumptions, or at least without checking the veracity of each claim we made.